OceanBase 自适应合并
LSM Tree与读写放大
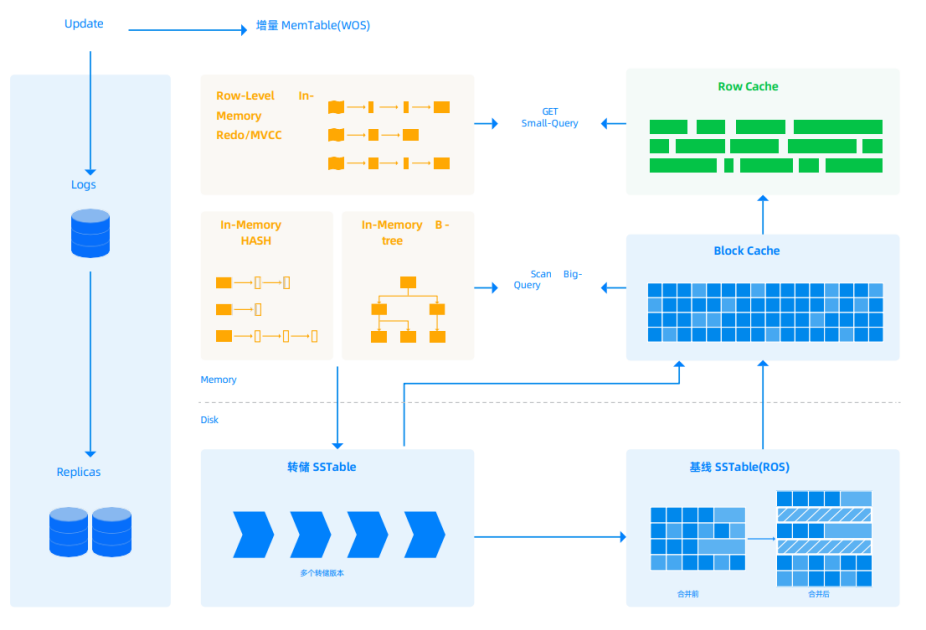
OceanBase的存储
要理解Compaction,必须先理解LSM-Tree存储架构。OceanBase是一款“准内存数据库”,它基于LSM-Tree设计,将数据分为两部分:内存中可变的动态增量数据(MemTable)和磁盘上不可变的静态基线数据(SSTable)。
写入路径:当有数据写入(INSERT/UPDATE/DELETE)时,OceanBase并不会直接修改磁盘上的旧数据,而是采用Append-only的方式,将新的数据版本写入内存中的MemTable。这种方式避免了随机写操作,使得写入性能非常高效。
读取路径:读取数据时,系统需要整合内存和磁盘上可能存在的所有数据版本,才能返回用户一个正确且一致的结果。如果磁盘上的数据分层、版本过多,这个过程就需要访问多个SSTable,从而导致读放大问题,严重影响查询性能。
Compaction的作用:
为了解决上面提到的读放大的问题,LSM-Tree提出了Compaction机制。定期地对存储在不同层级的数据进行合并与整理,具体目标包括:
·合并数据:将多层、多个SSTable文件合并,减少查询时需要扫描的文件数量。
·回收空间:物理删除那些被标记为“删除”或已过时的旧版本数据,释放磁盘空间。
·提升性能:通过上述操作,最终缩短查询路径,大幅提升读取性能。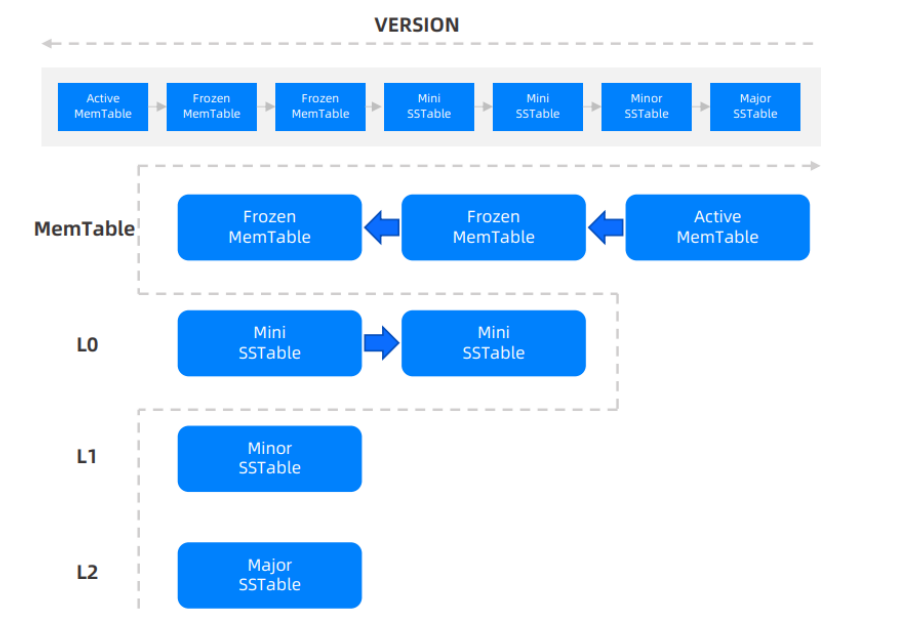
常见的分层Compaction
Mini Compaction(转储)
。触发: 当一个租户的MemStore内存使用率超过freeze_trigger_percentage配置的阈值时(默认为20%),系统会自动触发转储。也可以通过ALTER SYSTEM MINOR FREEZE命令手动触发。
。过程 :系统会将内存中的Active MemTable“冻结”(不再接受新写入),并将其中的增量数据持久化到磁盘,形成L0层的Mini SSTable。
。特点 :这是一个租户级、OBServer级的轻量级操作,主要目的是快速释放内存,但它不会回收多版本数据。
·Minor Compaction
。触发: 当L0层的Mini SSTable数量超过minor_compact_trigger(默认为2)时,或L0层数据量与L1层数据量达到一定比例时,系统会自动触发。此操作无法手动执行。
。过程: 将L0层的多个Mini SSTable,或L0层与L1层的Minor SSTable进行合并,生成一个新的L1Minor SSTable。
。特点: 分区级别的自动操作,会回收部分多版本数据,目的是减少增量SSTable的数量,提升查询效率。
·Major Compaction(合并)
。触发: 通常由major_freeze_duty_time参数控制,每日定时(默认凌晨2点)在业务低峰期执行。也可以手动执行或在转储次数达到major_compact_trigger阈值后自动触发。
。过程 :这是一个重量级操作,它会将该租户在所有副本上的所有数据(包括MemTable、L0/L1/L2的SSTable)进行一次彻底的归并,形成一份全新的、版本统一的基线数据(MajorSSTable)。
。特点: 全局操作,资源消耗大,但效果也最彻底。它会彻底清除所有无效数据,并进行高效的编码压缩,最大程度地节省存储空间和优化查询性能。
| 特性 | Mini Compaction(转储) | Minor Compaction | Major Compaction |
| 级别与范围 | 租户级(自动)/分区级(手动) | 分区级 | 租户级全局 |
| 触发机制 | 内存使用率阈值/手动 | Mini SSTable 数量/数据量 | 定时/转储次数/手动 |
| 多版本回收 | 不回收 | 回收 | 回收 |
| 数据压缩 | 通用压缩 | 通用压缩 | 编码压缩+通用压缩 |
Buffer表与自适应合并
什么是“Buffer表”?
·现象: 在业务当中有这种情况:一张表的总行数并不多,但随着业务运行,对这张表的查询和更新却越来越慢,甚至出现性能瓶颈。这种现象在OceanBase中被称为Buffer表。
·原因:正是由于LSM-Tree架构造成的写放大。对于这类频繁UPDATE或INSERT后紧接着DELETE的表,虽然逻辑上行数很少,但在物理存储上,旧版本的数据行只是被标记删除,并未立即被清理。磁盘上的物理行数远多于逻辑行数,导致查询时需要扫描和过滤海量的“垃圾”数据,造成了严重的读放大,性能自然下降。
·传统方案的痛点: 虽然每日的Major Compaction最终能清理这些垃圾数据,但它是全局性的,执行周期长,无法灵活、及时地响应单个热点表的性能恶化问题。
自适应合并
为了解决这一痛点,OceanBase V4.2.0版本引入了“自适应合并”机制。
·是什么: 它是一种分区级别的、由系统自动触发的轻量级合并。OceanBase会根据分区的读写行为,智能地识别出类似Buffer表这样的、可能导致慢查询的场景,并主动对该分区调度合并任务。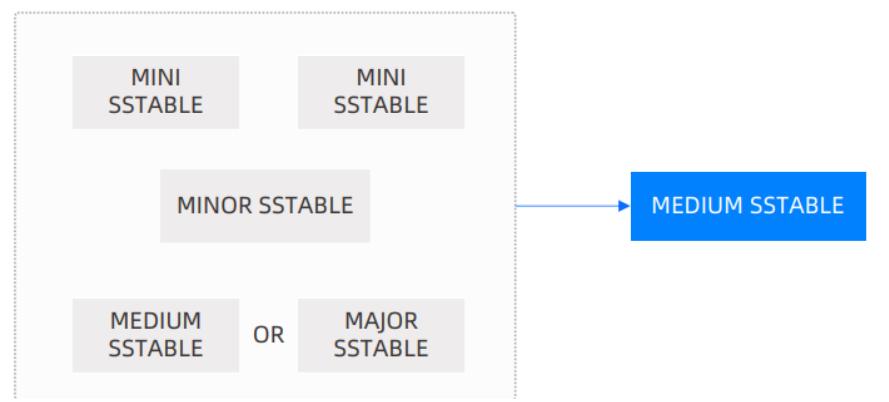
如何合理使用自适应合并?
自适应合并的配置
对于全局的自适应合并,自适应合并功能由租户级隐藏配置项 _enable_adaptive_compaction 进行控制,默认为开启状态。
全局的自适应合并默认粒度是租户,假如想要从表的角度更加设置自适应合并的触发概率,用户可以通过为每张表设置不同的table_mode值以便指定不同的快速冻结与自适应合并策略以应对Buffer表问题。
1 | --创建时指定 |
·策略选择: table_mode提供了多个等级,触发合并的概率从低到高:
。 normal (默认值):极低概率触发。
。 queuing:低概率触发,适合有明显Queuing表特征的场景。
。 moderate:中等概率。
。 super/extreme:高/极高概率,会消耗更多系统资源。
对于table_mode这么多个选项在实际情况下对于合并的触发概率到底是怎么样,会触发什么样的合并。
分析
通过源码分析,自适应合并触发的阈值如下,当update+delete 或者delete达到一定的操作行数之后就会触发自适应合并。

这个过程当中自适应合并触发了什么merge?
queuing级别以及以下产生的merge。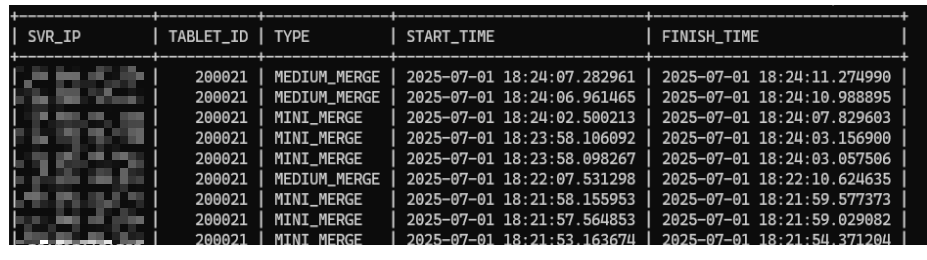
queuing级别以上产生的merge。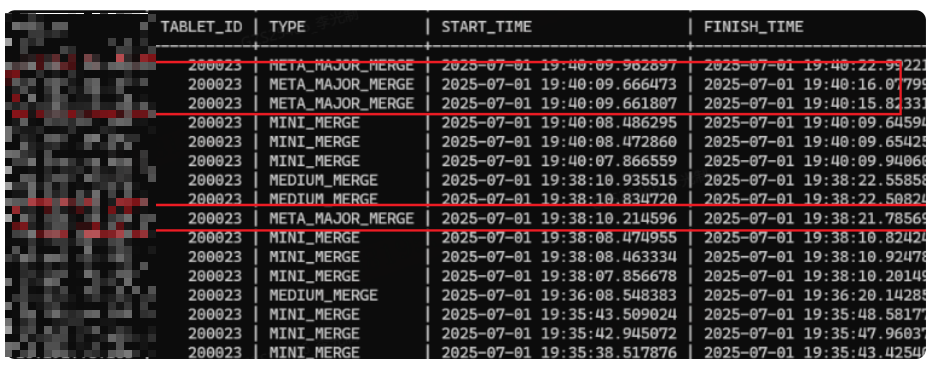
通过测试发现,modrate(不包含)以下,自适应合并只会进行MEDIUM_MERGE,在modrate以及以上的table_mode的级别会同时使用MEDIUM_MERGE和META_MAJOR_MERGE,通过查看源码发现和测试的结果也是一致的,在modrate(不包含)以下并不会使用META_MAJOR_MERGE。
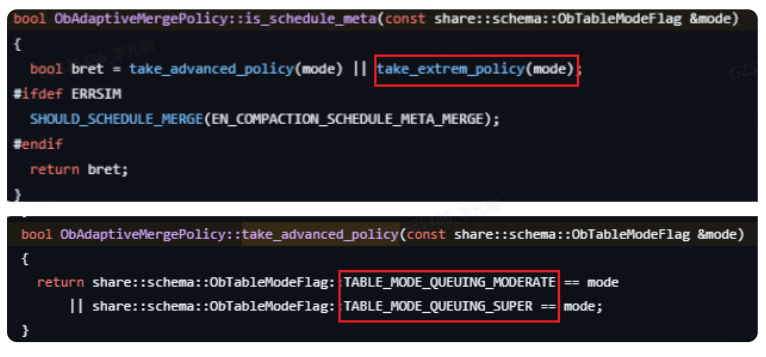
不常见的Compaction
上面提到的MEDIUM_MERGE和META_MAJOR_MERGE分别是什么,和之前提到的常见的Compaction有什么区别。
MEDIUM_MERGE
MEDIUM_MERGE只会让某一个分区的所有副本执行将所有Mini SStable (Minor SStable),和旧Major SStable共同合成一个新Major SSTable的compact过程,可以把他称为“分区级合并”。
META_MAJOR_MERGE
META_MAJOR_MERGE只需要在某个分区的某个副本内,执行一次将所有Mini SStable(Minor SStable),和旧Major SStable共同合成一个新Meta Major SSTable(这里的Meta Major SSTable和Major SSTable类似,但是是可以和Major SSTable共同存在的SSTable,不需要保证多副本的一致)的compact 过程,这个特殊的过程能够在加速查询的同时极大地减少整理数据的开销。
总结
使用自适应合并时从低到高逐级调整table_mode值,谨慎使用exterme模式,因为exterme模式下触发delete阈值和super差距很大,如果想自适应合并发生的副本级别,建议table_mode调至modrate以及以上,modrate以下不会触发副本级别的合并。
管理与监控
4.1关键配置参数解读
Compaction触发:
freeze_trigger_percentage:控制Mini Compaction的内存阈值。
major_freeze_duty_time:控制每日Major Compaction的执行时间。
并发线程数:
compaction_high_thread_score, compaction_mid_thread_score,
compaction_low_thread_score:分别控制高、中、低优先级Compaction任务(对应Mini、Minor、Major)的并发线程数。在转储压力大时,可适当调高compaction_high_thread_score来加速转储。
4.2实用监控视图与SQL
OceanBase提供了丰富的系统视图来监控Compaction状态。
DBA_OB_MAJOR_COMPACTION:查看租户的全局合并状态信息。
GV$OB_TABLET_COMPACTION_PROGRESS:实时查看分区级别的Compaction进度。
GV$OB_TABLET_COMPACTION_HISTORY:查看历史分区的Compaction。