MySQL深分页优化
下文所有内容基于以下表结构
1 | CREATE TABLE `user` ( |
使用Navicat生成1000000条数据
深分页是什么?
在了解深分页优化之前,我们要知道深分页是什么?为什么要去优化深分页?
假设查询SQL如下
1 | select id,name,password,gender from user where create_time < '2016-11-07' LIMIT 300000,10 |

1 | select id,name,password,gender from user where create_time < '2016-11-07' LIMIT 1,10 |

发现相较于第二条SQL,第一条SQL的执行时间慢了接近10倍。
是什么原因导致的慢SQL?

通过执行计划发现这条SQL的扫描方式为range(索引范围扫描)
执行流程如下
通过非聚集索引找到符合条件的行的ID。
通过找到的ID,在聚集索引中找到所有的行(回表查询),过滤前300010行,返回最后10条结果。
发现慢SQL的原因无非是offset过大,造成了先读取offset + n行数据,然后返回最后的n行。这意味着随着offset值的增长(即翻页越深),MySQL不得不扫描并忽略越来越多的无关行,效率随着分页深度增加而急剧下降。
如何优化
1.子查询
1 | SELECT |

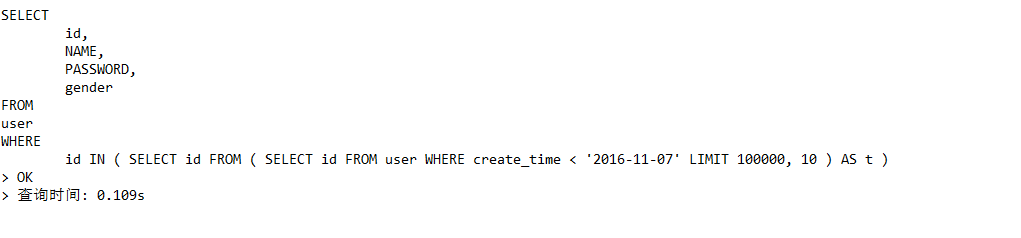
时间优化了10倍
2.游标分页
1 | select id,name,password,gender from user where create_time < '2016-11-07' ORDER BY id LIMIT 200090,10 |
假设上述查询最后一条结果id为76521,我们可以通过下面这个SQL翻到下一页
1 | select id,name,password,gender from user where create_time < '2016-11-07' and id > 76521 ORDER BY id LIMIT 300000,10 |

因为命中了id索引,所以性能也不会差。
缺点:
- 不能跳页,只适合C端场景不适合B端场景。
- 需要一个连续自增的字段